Running Llama 3.1 on an AMD 6700 XT: My LLM App Journey
Running large language models (LLMs) is generally smooth sailing if you have an Nvidia GPU or a newer AMD card (7xxx series). Sadly, I wasn’t so fortunate. Here’s my experience trying to get an LLM running on my hardware.
Ollama (v0.2.8)
Ollama was my first attempt. Since it primarily runs on the CPU and doesn’t support my GPU, it was painfully slow. I scoured the internet for solutions, searching terms like:
- “ollama rx 6700 xt”
- “ollama with rx 6700 xt windows”
- “ollama rocm”
- “ollama rocm windows”
Most of the tips I found were Linux- and Docker-focused. I tried Docker with this command:
Bash
docker run -d --restart always --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama -e HSA_OVERRIDE_GFX_VERSION=10.3.0 -e HCC_AMDGPU_TARGET=gfx1030 ollama/ollama:rocm
Unfortunately, I encountered numerous errors. I updated my ROCm software, installed modified files, and tried various troubleshooting steps, but nothing worked. With my limited Docker experience, I reluctantly gave up after a couple of hours.
LM Studio (v0.2.28)

LM Studio looked incredible, packed with all the features I could want. The website mentioned AMD GPU support, but to my disappointment, it didn’t work with my 6700 XT. I tried some tweaks, but with no luck. I’m hopeful that future versions will expand their GPU compatibility.
GPT4All (v3.0.0)

GPT4All was a simple, CPU-based option with a nice UI. However, it seemed to use more CPU resources than expected when generating responses.
Backyard AI (Version Unknown)
Backyard AI recognized my GPU, but it oddly consumed a lot of CPU, RAM, and VRAM, even maxing out my VRAM. This caused responses to get cut off, making it unusable for me. Here’s what it reported:
Bash
nvidia: NVIDIA START
NVIDIA END
openCL: OPENCL START
<<<gfx1031>>>, <<<AMD Radeon RX 6700 XT>>>, 0, 0, 4098, 12868124672, 12551364
OPENCL END
vulkan: VULKAN START
<<<AMD Radeon RX 6700 XT>>>, 0, 4098, 12868124672
VULKAN END
Koboldcpp_ROCM: The Winner

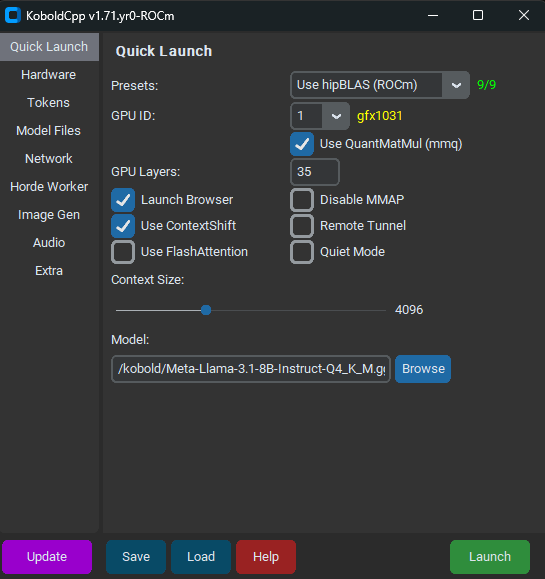
Finally, I discovered Koboldcpp_ROCM – a fork of KoboldCpp specifically for AMD GPUs. It ran smoothly on Windows, utilized my GPU and VRAM effectively, and allowed me to experience a fast, local LLM. While seemingly designed for roleplaying, it worked well as a personal assistant and offered an API for further integration.
On Windows, it was a single executable. After loading a GGUF model, it worked out of the box with a basic web UI (not ideal for code). I ended up pairing it with SillyTavern for a better interface.
Final Thoughts
For now, Koboldcpp_ROCM is my go-to LLM solution. If other apps expand their support for older GPUs like mine, I’ll definitely reconsider. But for the time being, I’m happy to have found a functional setup.
Let me know if you’d like any other refinements to your blog post!